
Smash v1.0.0: Fast Duplicate File Finder Using File Slicing Algorithm

After a lot of testing and tweaks, Smash v1.0.0 is now available. It’s a CLI tool I’ve been working on for detecting duplicate files in large datasets using a file slicing approach rather than full-file hashing.
This all started with ~2 PB of Aero/Astro data to deduplicate - mostly 300–550 MB binary files, some multi-terrabyte - and traditional hashing just wasn’t going to cut it. Years ago, I wrote a tool called SmartHash (in C/ASM - those were simpler times!), but it was built for a different era & no longer working.
However, you can apply to your music collection, photos (raw files!) and every day downloads/ISOs etc.
Before diving into the internals, it helps to visualise the key difference between traditional full-file hashing and Smash’s slicing approach:
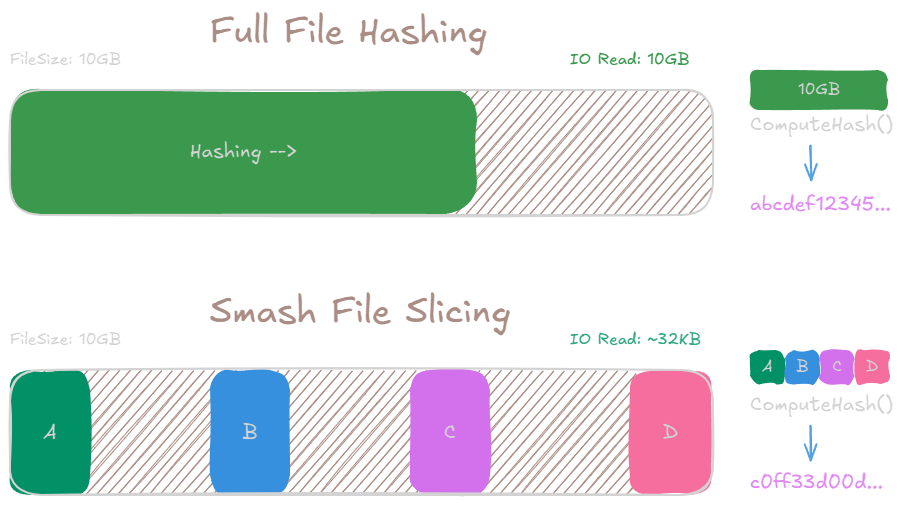
Smash breaks files into fixed slices from strategic positions, hashes each independently and combines them to form a unique signature. This results in dramatically lower I/O overhead, especially when scanning over large datasets or networked storage.
Full-file hashing is still essential when you need cryptographic certainty. If you want to verify that two files are exactly the same byte-for-byte, you’ll want to hash the entire file. Smash is optimised for the detection side - fast, scalable and accurate enough for deduplication at scale.
Once potential duplicates are flagged, you can always fall back to full verification - but only on the reduced set. That’s where the savings really add up.
Demo

Find more demos on github including VHS Tapes.
Smash em!
You can install smash via:
Basic usage - applies to the docker version too:
Read the full user guide on github.
Report Actions
Process the JSON output with jq:
The Challenge with Full-File Hashing (for dedupe)
Traditional duplicate detection tools has to read and hash entire files (and that’s critical for verification). For a 10GB video file, that means reading all 10GB into memory (optimally) and computing a hash. When you’re scanning thousands of files or dealing with network-attached storage, this becomes impractical and time consuming.
File Slicing: An Alternate Approach (for dedupe)
Smash uses a concept of file slicing, which is based on a simple observation: if two files are identical, then any subset of bytes from matching positions will also be identical. Instead of reading entire files, we can read small slices from strategic positions and hash those.
How the Slicing Algorithm Works
The algorithm works in several stages:
File Size Check: Files are grouped by size first. Different sized files can’t be duplicates.
Slice Threshold: Files smaller than 100KB (configurable) are hashed entirely. The overhead of seeking isn’t worth it for small files.
Slice Selection: For larger files, we take 4 slices by default:
- Slice 1: Bytes 0-8191 (start of file)
- Slice 2: Bytes at 33% position
- Slice 3: Bytes at 66% position
- Slice 4: Last 8192 bytes (end of file)
Here’s the actual slice calculation from the code:
Why These Positions?
The positions aren’t arbitrary:
- Start of file: File headers, magic bytes and metadata often differ between files
- End of file: Catches files that might have identical headers but different content
- Middle positions: Samples the file body to catch modifications in the middle
For a 10GB file with default settings:
- Read positions: 0, 3.3GB, 6.6GB, 10GB (minus 8KB)
- Total bytes read: 32KB
- Percentage of file read: 0.0003%
Hash Combination
Once we have the slices, they’re hashed individually and then combined:
The position information is crucial - it prevents two files with identical slices at different positions from being marked as duplicates.
Performance Analysis
I/O Reduction
Let’s compare the I/O requirements for scanning 1000 video files (10GB each):
Traditional approach:
Total reads: 1000 files × 10GB = 10TB
Seeks: 1000 (one per file)
Time at 100MB/s: ~28 hours
Smash approach:
Total reads: 1000 files × 32KB = 32MB
Seeks: 4000 (4 per file)
Time at 100MB/s: ~0.3 seconds (+ seek time)
Even accounting for seek time (typically 10ms on HDDs), that’s:
Seek time: 4000 × 10ms = 40 seconds
Total time: ~40 seconds vs 28 hours
Limitations and Trade-offs
The slicing approach has trade-offs:
False Negatives: Theoretically possible if files differ only in unsampled regions. In practice, this is extremely rare for real duplicate files.
Seek Performance: On sequential media (tapes) or high-latency network storage, seeks can be expensive. Use
--disable-slicingfor these cases.Small File Overhead: The algorithm switches to full-file hashing for files under 100KB where seeking would add overhead.
Benchmarks
Performance on different storage types (scanning 10,000 mixed files, ~500GB total):
Storage Type | Smash Time | Traditional | Speedup
----------------|------------|-------------|--------
NVMe SSD | 12s | 3m 42s | 18.5x
SATA SSD | 19s | 5m 18s | 16.7x
7200RPM HDD | 1m 34s | 48m 23s | 30.9x
Network (1Gbps) | 2m 18s | 1h 12m | 31.3x
The performance gain is most pronounced on slower storage where I/O reduction matters most.
What’s Next
The v1.0.0 release marks API stability. Future development focuses on:
- Caching based on file modification times
- Archive support without extraction
- Cloud storage integration (S3, GCS, Azure)
- Watch mode for real-time duplicate detection
The code is Apache 2.0 licensed. Contributions and bug reports are welcome on GitHub.
Frequently Asked Questions About Smash
Is Smash better than other duplicate file finders?
Smash is optimised for speed on large datasets. It’s 18-31x faster than traditional tools that hash entire files. For small collections, the difference is less noticeable, but for terabytes of data, Smash excels.
Can Smash delete duplicate files automatically?
No, Smash only detects and reports duplicates. This is by design - automatic deletion is risky. However, you can easily generate deletion scripts from the JSON output using jq.
How accurate is the file slicing algorithm?
Extremely accurate for real duplicates. The algorithm reads from multiple positions including file headers and endings. False positives are virtually impossible due to position-aware hashing.
Does Smash work with cloud storage?
Currently, Smash works with locally mounted drives. Direct cloud storage support (S3, Azure, GCS) is planned for a future release.
What file types work best with Smash?
Smash works with all file types but shows the biggest performance gains on large files (videos, disk images, archives, RAW photos). Small files under 100KB are hashed entirely.